Introducing the Sohu AI chip, a groundbreaking development by Etched, founded by Harvard dropouts Gavin Uberti and Chris Zhu.
Engineered specifically for transformer models, Sohu leverages TSMC’s 4nm process to deliver unparalleled performance and energy efficiency.
This chip significantly outpaces Nvidia’s next-generation Blackwell B200 GPUs, processing over 500,000 tokens per second on the Llama 70B model.
Consuming only 10 watts of power, Sohu is an ideal choice for businesses aiming to optimize their AI operations.
Its high throughput and efficiency are set to revolutionize industries, setting a new benchmark for advanced AI solutions.

Screenshot taken from Etched
Subscribe below to get latest AI News
The Technological Marvel Behind Sohu
Sohu is built using TSMC’s 4nm process, a cutting-edge technology that promises high performance and energy efficiency. This advanced manufacturing technique allows Sohu to achieve speeds and cost-efficiency that were previously thought unattainable.
Compared to Nvidia’s next-generation Blackwell B200 GPUs, Sohu is significantly faster and more cost-effective when running transformer-based models.
Unparalleled Performance
One of Sohu’s standout features is its remarkable throughput. It can process over 500,000 tokens per second on the Llama 70B model, a feat that enables the creation of products previously impossible with traditional GPUs.
To put this into perspective,
A single 8xSohu server can replace 160 H100 GPUs
Moreover, Sohu’s energy consumption is astoundingly low, using only 10 watts of power while delivering its high performance. This makes it an excellent option for businesses aiming to optimize their AI operations both in terms of performance and cost.
Screenshot taken from Etched
Reason of High efficiency and low power consumption
Sohu achieves its high efficiency and low power consumption through several factors:
Specialized Design: Sohu is specifically designed to run transformer models, which are a type of neural network architecture. By focusing on a single type of model, Sohu can optimize its hardware for that specific use case, resulting in higher efficiency compared to general-purpose GPUs that need to handle a wide range of tasks.
ASIC (Application-Specific Integrated Circuit): Sohu is an ASIC, which means it’s a custom-designed chip that’s optimized for a specific application (in this case, transformer models). ASICs can be more efficient than general-purpose chips like GPUs because they can eliminate unnecessary components and focus on the specific requirements of the target application.
4nm Process Technology: Sohu is built using TSMC’s 4nm process, which is a cutting-edge manufacturing technology. The smaller the process node, the more transistors can be packed into a chip, resulting in higher performance and efficiency.
Transformer Model Optimization: Sohu’s architecture is designed to efficiently execute the mathematical operations required by transformer models, such as matrix multiplications and attention mechanisms. This optimization allows Sohu to perform these operations more efficiently than general-purpose GPUs.
Low Power Consumption: Sohu’s power consumption is significantly lower than that of GPUs. According to the information provided, Sohu consumes only 10 watts of power, which is much lower than the power consumption of high-end GPUs. This is possible due to the factors mentioned above, as well as other design choices and optimizations.
The Specialized Edge
Sohu is the first specialized chip (ASIC) designed for transformer models. This specialization allows it to outperform general-purpose GPUs by a significant margin. While Sohu cannot run other types of AI models like CNNs, LSTMs, or SSMs, its focus on transformers results in a substantial performance boost.
Today, every major AI product, including ChatGPT, Claude, Gemini, and Sora, is powered by transformers. This trend suggests that in the near future, every large AI model will be run on custom chips like Sohu.
Why Specialized Chips Are the Future
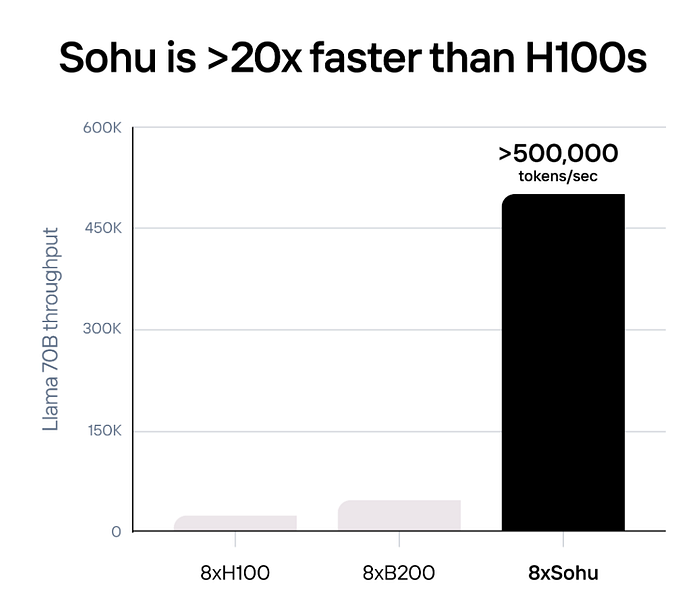
The shift towards specialized chips is inevitable for several reasons. Sohu is more than 10 times faster and cheaper than even Nvidia’s next-generation Blackwell (B200) GPUs. Specifically, one Sohu server processes over 500,000 Llama 70B tokens per second, 20 times more than an H100 server (23,000 tokens/sec), and 10 times more than a B200 server (~45,000 tokens/sec).
Screenshot taken from Etched
These benchmarks are based on running in FP8 without sparsity at 8x model parallelism with 2048 input/128 output lengths. The performance figures for 8xH100s are sourced from TensorRT-LLM 0.10.08 (the latest version), and the 8xB200 figures are estimated.
This same benchmark methodology is used by industry giants like Nvidia and AMD.
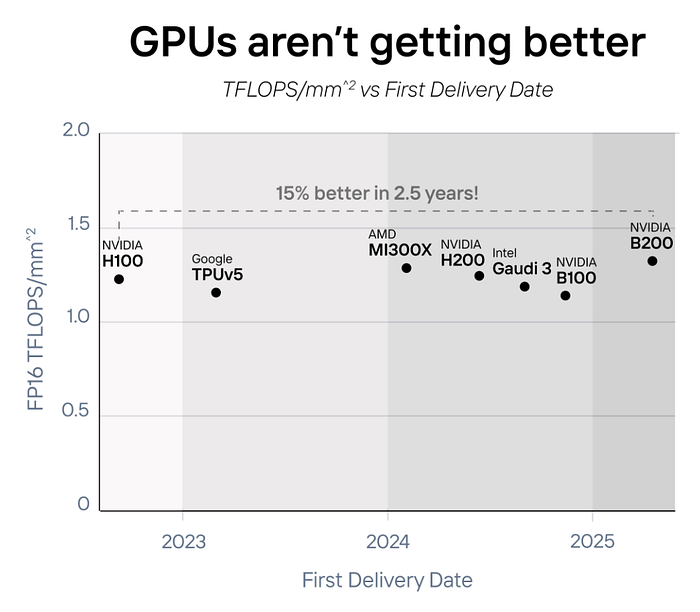
The Stagnation of GPU Improvements
Over the past four years, the improvement in compute density (TFLOPS/mm²) for GPUs has been a mere 15%. Next-generation GPUs from companies like Nvidia (B200), AMD (MI300X), and Intel (Gaudi 3) are now resorting to counting two chips as one card to “double” their performance. With Moore’s law slowing down, the only way to achieve significant performance improvements is through specialization.
The Changing Economics of AI
Today, AI models cost over $1 billion to train and are used for $10 billion or more in inference.
At this scale, even a 1% improvement can justify a $50–100 million custom chip project. ASICs, like Sohu, are 10–100 times faster than GPUs.
This economic rationale mirrors the shift seen in the cryptocurrency mining industry in 2014, where it became cheaper to discard GPUs in favor of ASICs designed specifically for mining.
The Dominance of Transformer Models
Transformers have created a substantial competitive advantage.
The concept of the hardware lottery suggests that the architecture which runs fastest and cheapest on hardware wins. Transformers have indeed won this lottery.
AI labs have invested hundreds of millions of dollars optimizing kernels for transformers.
Startups are utilizing specialized transformer software libraries like TRT-LLM and vLLM, which offer features built on transformers, such as speculative decoding and tree search.
The Future of AI Hardware
As AI models scale from $1 billion to $100 billion training runs, the risk of testing new architectures increases. Consequently, efforts are better spent on making transformers more efficient rather than re-testing scaling laws.
Once Sohu and other ASICs become mainstream, we will reach a point of no return. For any new architecture to compete, it must run faster on GPUs than transformers do on Sohu.
If that happens, the industry will simply build an ASIC for that architecture as well.
Sohu vs. Blackwell: A Comparative Analysis
Etched’s Sohu chip is claimed to be significantly faster and more cost-effective than Nvidia’s next-generation Blackwell B200 GPUs when running transformer-based models. Specifically, it is stated that Sohu is over 10 times faster and cheaper than the Blackwell B200 GPUs.
It is also mentioned that a single Sohu server can process over 500,000 tokens per second on the Llama 70B model, which is 20 times more than an Nvidia H100 server (23,000 tokens per second) and 10 times more than a B200 server (~45,000 tokens per second).
These comparisons suggest that Sohu has a significant performance advantage over Nvidia’s Blackwell B200 GPUs, particularly in the context of transformer-based models.
Future Prospects
Looking ahead, the introduction of Sohu could accelerate the transition to custom AI chips across the industry.
As AI models become more complex and costly to train, the demand for efficient, specialized hardware like Sohu will likely grow.
This shift promises to redefine the landscape of AI development, making sophisticated AI applications more accessible and affordable.
As the demand for AI continues to grow, specialized chips like Sohu will become increasingly crucial, paving the way for more advanced and capable AI solutions.
If you want more updates related to AI, subscribe to our Newsletter