Key Takeaways
JEST achieves AI training with up to 13 times fewer iterations and 10 times less computational power than traditional methods, significantly speeding up the process.
The JEST method drastically reduces energy consumption, addressing the growing concerns about the environmental footprint of AI training.
Unlike conventional techniques, JEST selects entire batches of data for training, optimizing the learning process and improving performance.
JEST relies on a highly curated initial dataset to guide the training on larger, messier datasets, ensuring efficiency without sacrificing quality.
With AI workloads consuming increasing amounts of power, JEST could help mitigate these demands, reduce costs, and enhance sustainability in AI development.

Image taken from https://www.youtube.com/watch?v=rD7MyNdyi_A
DeepMind, Google’s AI research lab, has introduced a revolutionary AI training method called JEST (Joint Example Selection and Trust). This innovative approach promises to significantly enhance training efficiency and reduce resource consumption, addressing both financial and environmental concerns associated with AI development.
The Challenges of Traditional AI Training
Resource Intensive
Training AI models, such as GPT-3, demands substantial computing power and time. The process involves massive datasets and iterative learning, making it both time-consuming and expensive.
Environmental Impact
The energy consumption for training large AI models is immense, drawing comparisons to Bitcoin mining. This has raised concerns about the environmental impact, given the significant carbon footprint associated with such energy demands.
How JEST Works
Batch Data Selection
Traditional AI training methods focus on individual data points. JEST, however, selects groups or batches of data that work well together, optimizing the learning process.
Multimodal Contrastive Learning
JEST employs a multimodal contrastive learning approach, examining different types of data (such as images and text) together. This method identifies dependencies between data types, accelerating the learning process.
Pre-trained Reference Model
JEST starts with a pre-trained reference model that guides the AI towards high-quality data. This pre-selection enhances the efficiency of the training process, ensuring that the AI focuses on the most relevant and useful information.
Efficiency Gains
According to DeepMind, JEST achieves the same performance levels as traditional methods but requires up to 13 times fewer iterations and 10 times less computational power. This efficiency translates to faster training times and reduced resource consumption.
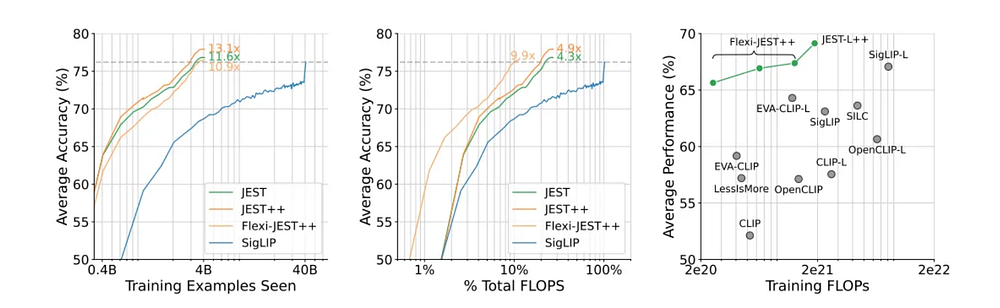
Image taken from Google
Data Quality Bootstrapping
High-Quality Initial Data
JEST begins with a small, highly curated dataset that guides the training on larger, messier datasets. This ensures that the training process is efficient without compromising on data quality.
Versatility
JEST has demonstrated effectiveness across various benchmarks, indicating its broad applicability in different AI training scenarios.
Industry Implications
Power Demands
AI workloads are increasingly consuming large amounts of power, with projections indicating even greater demands in the future. Methods like JEST could help mitigate these power requirements.
Environmental and Financial Impact
By reducing power consumption, JEST can ease the environmental impacts of AI training while also cutting financial costs, making AI development more accessible and sustainable.
Challenges and Limitations
Data Requirements
JEST’s reliance on high-quality initial data may pose challenges for smaller developers who lack access to extensive resources. Acquiring such data can be a significant hurdle for these developers.
Adoption
While JEST shows great promise for large-scale AI projects, smaller AI initiatives might find it challenging to adopt this method due to its initial data requirements and potential complexity.
Competitive Landscape
Chinese AI Companies
At a recent AI conference, Chinese companies like SenseTime and Alibaba showcased significant advancements and made bold claims about their models’ performance. This highlights the intense global competition in the AI space.
Global Competition
Predictions suggest a future where a few major players dominate the large language model (LLM) space. Chinese firms are positioning themselves to be among these elite players, intensifying the competitive landscape.
Additional Insights
Google DeepMind’s recent research claims JEST can achieve impressive gains in both training speed and power efficiency. By focusing on batch data selection and starting with a high-quality curated dataset, JEST can surpass state-of-the-art models with significantly fewer iterations and computational power.
Power Demands and Environmental Impact
AI workloads consumed approximately 4.3 GW in 2023, nearly matching the annual power consumption of Cyprus. With AI’s power demands projected to take up a quarter of the US power grid by 2030, methods like JEST are critical for reducing the environmental impact of AI training.
Financial Considerations
Training large AI models is expensive, with GPT-4 reportedly costing $100 million. As future models approach the billion-dollar mark, firms are keen on methods like JEST to cut costs while maintaining or improving performance.
Adoption and Future Prospects
The adoption of JEST by major AI players remains to be seen. However, its potential to reduce power draw and improve training efficiency makes it a promising development in the AI space. Whether it will be used to reduce costs or to maximize training output will depend on the priorities of the adopting firms.
DeepMind’s JEST method represents a significant leap forward in AI training, addressing critical challenges of efficiency, resource consumption, and environmental impact. As the AI industry continues to grow and evolve, innovations like JEST will play a crucial role in shaping the future of technology.
If you want more updates related to AI, subscribe to our Newsletter