OpenAI has unveiled its latest AI model, GPT-4o, a groundbreaking development that integrates text, speech, and vision capabilities into a single, seamless AI experience. Announced on May 13, 2024, GPT-4o, where the “o” stands for “omni,” is set to revolutionize the way users interact with AI, making the experience more natural and intuitive than ever before.

All about GPT-4o
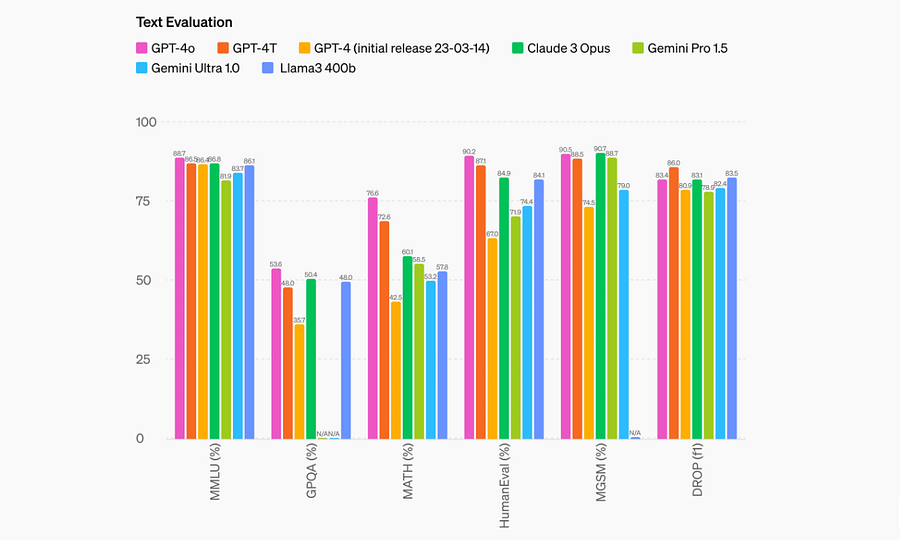
GPT-4o builds upon the foundation laid by GPT-4, delivering similar intelligence levels but with significant improvements across text, voice, and vision.
OpenAI CTO Mira Murati emphasized the importance of this development during a live presentation, stating, “GPT-4o reasons across voice, text, and vision. This is incredibly important because we’re looking at the future of interaction between ourselves and machines.”
The previous model, GPT-4 Turbo, could analyze and describe images in conjunction with text.
GPT-4o takes this a step further by integrating speech into the mix, enabling a variety of new applications.
Users can now interact with ChatGPT more like a real assistant, enjoying real-time responsiveness and the ability to interrupt and engage dynamically. GPT-4o can even pick up on vocal nuances and generate responses in different emotive styles, including singing.
Enhanced User Experience in ChatGPT
One of the most notable enhancements is the improved experience in OpenAI’s AI-powered chatbot, ChatGPT. The platform’s existing voice mode, which transcribes the chatbot’s responses using a text-to-speech model, has been significantly upgraded.
With GPT-4o, users can ask questions and receive more interactive and emotionally responsive answers. The model’s real-time capabilities allow for seamless interruptions and adjustments during conversations.
GPT-4o is not only effective in providing direct answers but also capable of reasoning through problems with a limited number of examples, making it a versatile and powerful language model.
Moreover, GPT-4o enhances ChatGPT’s vision capabilities. Users can present photos or desktop screens, and ChatGPT can quickly answer related questions, such as identifying brands or interpreting software code.
This functionality is set to evolve further, potentially allowing the AI to “watch” live events and provide explanations or commentary.

Improved Multilingual and Audio Capabilities
GPT-4o is designed to be more multilingual, supporting around 50 languages with enhanced performance. It is also twice as fast and half as costly as GPT-4 Turbo, with higher rate limits. While the new audio capabilities will initially be available to a small group of trusted partners, broader access is expected to follow.
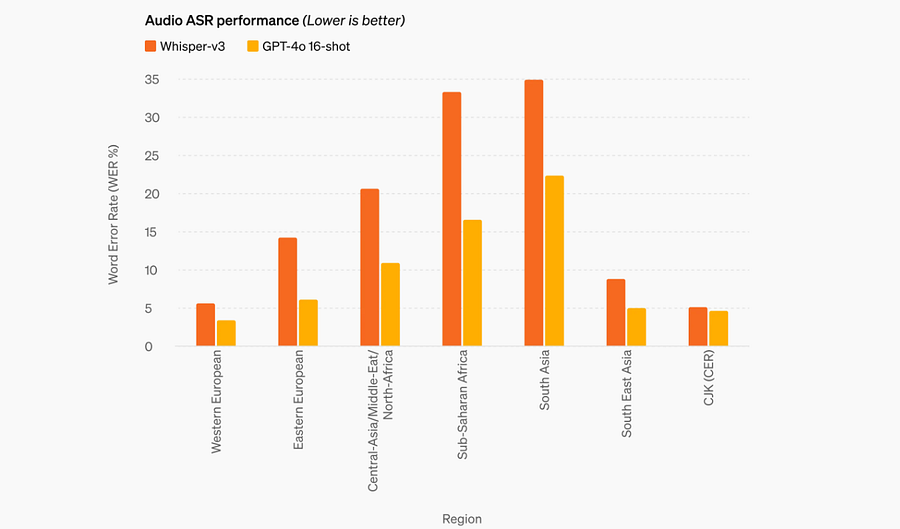
GPT-4o outperforming Whisper-v3
GPT-4o has set a new state-of-the-art in speech translation, outperforming Whisper-v3 on the MLS benchmark.
This advancement is particularly significant because it highlights GPT-4o’s ability to understand and generate across text, audio, and vision in real-time, making it a truly multimodal AI model.
The incorporation of Whisper into GPT-4o might have played a crucial role in improving its performance, especially in terms of latency and speech recognition capabilities across all languages, including lower-resourced ones.
This development indicates a major leap forward in AI technology, promising a more inclusive and accessible AI landscape that can cater to diverse global audiences by breaking down linguistic barriers.

Performance in the M3Exam Benchmark
The M3Exam benchmark is a comprehensive test designed to assess a model’s proficiency in understanding and answering questions from official exams across multiple languages, including those requiring the processing of images. GPT-4o has shown superior performance compared to its predecessor, GPT-4, across all languages in the M3Exam benchmark.
This improvement indicates GPT-4o’s enhanced capability to handle multilingual text, even in low-resource and non-Latin script languages, as well as its ability to process and understand visual information.
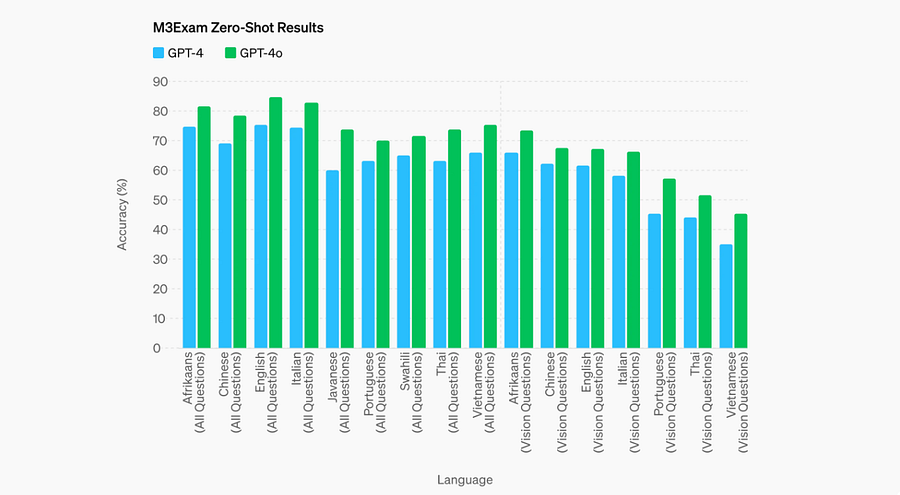
However, it’s important to note that for Swahili and Javanese, the vision results were omitted due to the limited number of vision questions available for these languages.
This indicates that there is still room for improvement in terms of assessing and enhancing the model’s performance in handling visual information across a wider range of languages.
The M3Exam benchmark serves as a valuable tool for evaluating the progress and limitations of language models like GPT-4o, highlighting the importance of multilingual and multimodal understanding in achieving a more comprehensive and inclusive AI.
Availability and Access
GPT-4o is available immediately in the free tier of ChatGPT and to subscribers of OpenAI’s premium ChatGPT Plus and Team plans, with higher message limits for these users. The improved ChatGPT voice experience will arrive in alpha for Plus users within the next month. Enterprise-focused options will be introduced subsequently.
In conjunction with the new model, OpenAI has refreshed the ChatGPT user interface on the web, introducing a more conversational home screen and message layout. A desktop version of ChatGPT for macOS is also now available, with a Windows version planned for later in the year.
Expanding Features for Free Users
The GPT Store, OpenAI’s library and creation tools for third-party chatbots built on its AI models, is now accessible to users of ChatGPT’s free tier.
Additionally, features previously behind a paywall, such as memory capabilities, file and photo uploading, and web searches, are now available to free users.
Technical Advancements
GPT-4o is OpenAI’s first model to process text, vision, and audio inputs and outputs with the same neural network, allowing for more nuanced and integrated responses.
The model can respond to audio inputs in as little as 232 milliseconds, with an average response time of 320 milliseconds, comparable to human conversation speeds.
Previously, Voice Mode required a pipeline of separate models for transcription and response generation.
GPT-4o’s end-to-end training across modalities means it can directly observe and respond to tonal changes, multiple speakers, and background noises, providing a richer interaction experience.
Demonstrations and Future Potential
During the launch event, OpenAI showcased GPT-4o’s capabilities through various demonstrations, including calming a user before a public speech and analyzing facial expressions to gauge emotions. The model can tell stories with different emotional tones and even sing.
As OpenAI continues to explore GPT-4o’s potential, the model’s ability to solve math problems, help with coding, and function as a translator was highlighted. It offers a robust toolset for developers and users alike, positioning it as a formidable competitor to other AI assistants on the market.
Industry Implications and Ethical Considerations
OpenAI’s advancements come amid a competitive landscape, with major players like Microsoft and Google also vying for dominance in the generative AI market. The rapid development and deployment of such advanced models raise ethical concerns about the technology’s impact and potential misuse.
OpenAI aims to mitigate these risks by initially launching GPT-4o’s audio capabilities to trusted partners and emphasizing transparency and user education. The company remains focused on making AI interactions more natural and user-friendly while navigating the complex ethical landscape.
Conclusion
OpenAI’s GPT-4o marks a transformative advancement in AI technology, integrating text, audio, and vision into a cohesive and responsive model. This development promises to make AI interactions more natural, engaging, and accessible, setting a new standard for multimodal AI systems. As GPT-4o rolls out to users and developers, its impact on AI applications and user experiences is poised to be profound and far-reaching.
If you want more updates related to AI, subscribe to our Newsletter