Let me introduce RouteLLM, an innovative project from lmsys.org designed to significantly reduce the cost of running large language models (LLMs) by up to 80% while maintaining 95% of GPT-4’s quality.
RouteLLM is an open-source framework crafted for cost-effective LLM routing, achieving high-quality results using smaller, open-source models.
Key Highlights
Balanced Cost and Performance: RouteLLM effectively balances cost and performance, offering near GPT-4 quality at a fraction of the cost.
Optimized Systems: The framework uses smaller, open-source models and agentic systems, managed by an orchestration layer, to optimize for quality, efficiency, cost, privacy, and security.
Local Computing: Most of the compute is pushed to local devices like phones and computers, with only necessary queries routed to more expensive models like GPT-4.
Future-Proof: As LLMs improve, more tasks can be handled locally, reducing overall costs.

Image from lmsys.org
RouteLLM is set to revolutionize LLM deployment by making them more accessible and cost-effective while maintaining high performance. The open-source nature of the project allows for further development and integration into various applications, marking a significant advancement in AI.
Efficient Query Handling with RouteLLM
Local models can handle 90–95% of queries effectively, reducing the need to rely on more expensive models like Claude or ChatGPT for only the most complex 5–10% of queries.
LLM routing offers an efficient solution by first processing each query through a system that determines which LLM should handle it, ensuring that manageable queries are routed locally, minimizing costs while maintaining response quality.
RouteLLM Framework
RouteLLM is a principled framework for LLM routing based on preference data, addressing the challenge of accurately routing queries. The framework involves:
Inference: Determining the characteristics of incoming queries and model capabilities.
Training: Using public data to train four different routers, demonstrating significant cost reductions without compromising quality.
Performance Metrics
MT Bench: Achieved over 85% cost reduction.
MLU: Achieved 45% cost reduction.
GSM AK: Achieved 35% cost reduction.
All benchmarks maintained 95% of GPT-4’s performance.
Evaluation and Results of RouteLLM
Experimental Setup
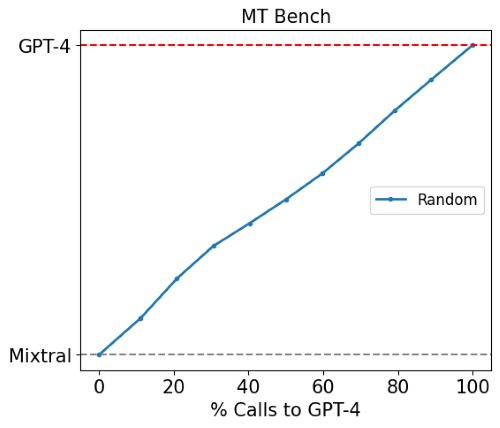
Image from lmsys.org
Models Used: GPT-4 as the strong model and Mixtral 8x7B as the weak model.
Baseline: A random router was used as a baseline for comparison.
Benchmark Evaluation
The performance of the RouteLLM framework was assessed using three popular benchmarks: MT Bench, MMLU, and GSM8K.
The evaluations focused on routing between GPT-4 Turbo as the strong model and Mixtral 8x7B as the weak model, using a random router as the baseline for comparison.
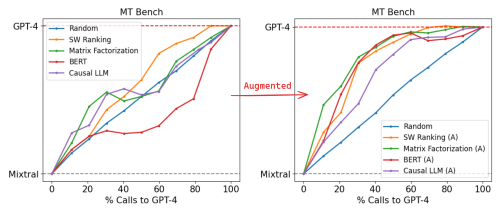
Image from lmsys.org
MT Bench Results
Router Performance on MT Bench
Arena Data Only: When trained solely on the Arena dataset, both matrix factorization and similarity-weighted (SW) ranking routers showed strong performance. The matrix factorization router achieved 95% of GPT-4 performance using only 26% of GPT-4 calls, resulting in a 48% cost reduction compared to the random baseline.
Augmented Data: Augmenting the Arena data with an LLM judge significantly improved performance across all routers. The matrix factorization router, in this case, achieved 95% of GPT-4 performance with just 14% of GPT-4 calls, making it 75% cheaper than the random baseline.
MMLU Results
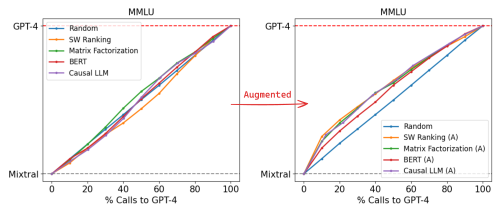
Image from lmsys.org
Router Performance on MMLU
Arena Data Only: On MMLU, routers performed poorly when trained only on Arena data due to the out-of-distribution nature of most questions.
Augmented Data: Augmenting the dataset with golden-label data from the MMLU validation split led to significant improvements. The best-performing causal LLM router required only 54% of GPT-4 calls to achieve 95% of GPT-4 performance, resulting in a 14% cost reduction compared to the random baseline. Notably, this improvement was achieved with just 1500 additional samples, demonstrating the high effectiveness of data augmentation even with a small dataset.
Comparison with Commercial Offerings
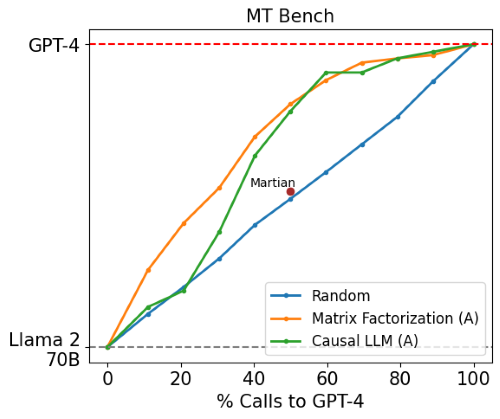
Image from lmsys.org
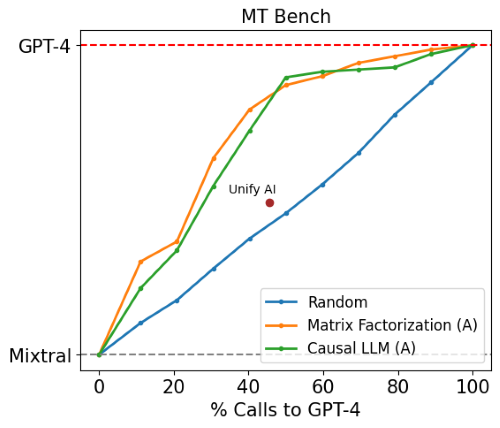
Image from lmsys.org
RouteLLM vs Commercial Systems
RouteLLM was compared against commercial routing systems Martian and Unify AI on MT Bench.
Performance and Cost: Using GPT-4 Turbo and either Llama 2 70B or Mixtral 8x7B, RouteLLM routers achieved similar performance to these commercial systems but were over 40% cheaper.
Generalization to Other Models
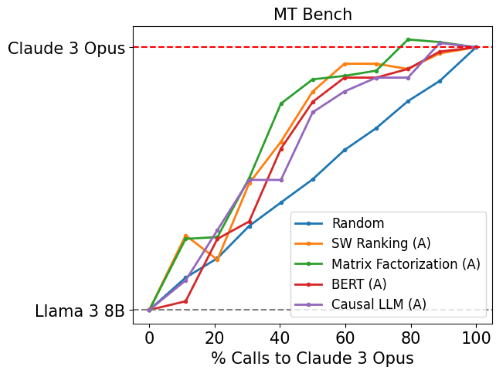
Generalization on MT Bench
To test generalizability, RouteLLM was evaluated on MT Bench with a different model pair: Claude 3 Opus and Llama 3 8B, without retraining the routers.
Results: The routers maintained strong performance, comparable to the original model pair evaluations. This indicates that RouteLLM’s routers can generalize effectively, distinguishing between strong and weak models even with new, unseen model pairs.
So, RouteLLM’s evaluations across multiple benchmarks and different model pairs demonstrate its robust performance, significant cost savings, and ability to generalize without retraining.
The framework’s use of data augmentation and preference data training methods ensures high-quality responses while optimizing costs, making it a valuable tool for deploying LLMs efficiently.
Exciting Benefits
Cost Reduction: Lowering the cost of using LLMs reduces energy consumption, making AI more accessible and enabling more applications to leverage AI in innovative ways.
Enhanced Techniques: Cheaper tokens allow for the frequent use of advanced techniques like mixture of agents and Chain of Thought, leading to more efficient and higher-quality AI usage.
Local Edge Devices: The framework promotes running AI on local edge devices, further improving efficiency and accessibility.
If you want more updates related to AI, subscribe to our Newsletter